
Nachwuchsgruppe: AI4BuildingModeling
Die DLR-Nachwuchsgruppe "AI4BuildingModeling - Künstliche Intelligenz für die 3D-Gebäudemodellierung" konzentriert sich darauf, leistungsstarke Computer-Vision-Methoden im Bereich der 3D-Fernerkundung zu entwickeln. Das Hauptziel besteht darin, die Extraktion und Rekonstruktion detaillierter Gebäudeinformationen aus Satellitenbildern zu ermöglichen, die für eine Vielzahl von Anwendungen wie die Verbesserung von OpenStreetMap (OSM) und CityGML-Daten, die Aktualisierung von Katasterdaten und die schnelle und zuverlässige Erstellung von 3D-Stadtmodellen genutzt werden können.
Die Integration detaillierter aus Fernerkundungsdaten gewonnenen Stadtinformationen in viele verschiedene Bereiche des Stadtmanagements bietet die Gelegenheit, einen wertvollen Beitrag für die Zukunft von smart cities zu leisten. Mit ihnen können die Auswirkungen der Urbanisierung kontrolliert, die städtische Umweltplanung unterstützt, der Energieverbrauch von Gebäuden analysiert werden und vieles mehr. Im Moment konzentriert sich die DLR Nachwuchsgruppe auf folgende Themen:
LoD2 Rekonstruktion
Unser Team verwendet Deep Learning, um in dicht besiedelten Gebieten grundlegende Gebäudeelemente und ihre Dachflächen innerhalb komplexer Strukturen zu identifizieren. Unter Verwendung von RGB-Bildern und Digitalen Oberflächen Modellen (DOM) und mit Hilfe unserer Modelle machen wir umfassende Vorhersagen zu Umrissen ganzer Gebäudestrukturen, den Trennlinien zwischen einzelnen Gebäudeelementen und Dachflächen. Diese semantischen Ausgaben werden dann unter Zuhilfenahme der Watershed-Transformation, sowie morphologischer Operatoren in Instanzen umgewandelt.
Diese werden wiederum – durch unseren innovativen Ansatz – in das Vektorformat überführt. Dies ermöglicht es uns, detaillierte Gebäudemodelle der Detailstufen 1 & 2 für anspruchsvolle städtische Gebiete zu erstellen. Um die Herausforderung zu meistern, dass es nur wenige hochwertig annotierte Daten für das Training gibt, setzen wir neueste unüberwachte und selbstüberwachte Techniken zur Klassifizierung verschiedener Arten von Gebäudedächern ein. Diese Klassifizierungen spielen eine entscheidende Rolle bei der 3D-Rekonstruktion, da wir anstreben, digitale Zwillinge mit in Level of Detail (LoD)-2 oder höher zu erstellen, selbst in sehr komplexen städtischen Szenarien.

Gebäude Geometrie Optimierung in DOMs
Photogrammetrische DOMs, die aus Stereobildern abgeleitet werden, liefern häufig Ergebnisse von geringer Qualität. Dies liegt an Problemen wie fehlerhaftem Matching in homogenen Bildregion und der begrenzten Erfassung von Informationen aus unterschiedlichen Blickwinkeln. Dies macht Aufgaben im Zusammenhang mit der Gebäuderekonstruktion sehr anspruchsvoll, da es in den meisten Fällen schwierig ist, den Dachtyp zu erkennen, insbesondere wenn das Gebäude von Bäumen überwachsen ist.
Unser Team entwickelt derzeit eine verbesserte GAN-Architektur (Generative Adversarial Network), mit der Gebäudestrukturen vollständig und detailliert rekonstruiert werden können. Erste Ergebnisse deuten darauf hin, dass die von uns vorgeschlagene Strategie zwei wichtige Ziele ohne manuelle Eingriffe erreichen kann: Sie verbessert die Dachflächen, indem sie sie ebnet und identifiziert und optimiert effizient kleine Wohngebäude, die üblicherweise schwer zu prozessieren sind.
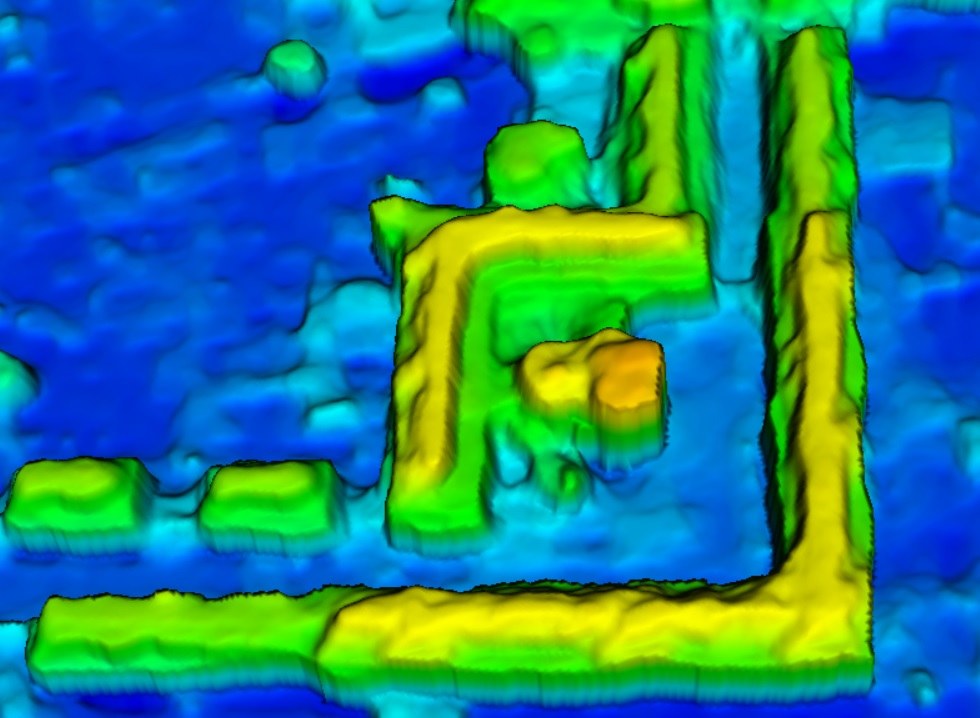


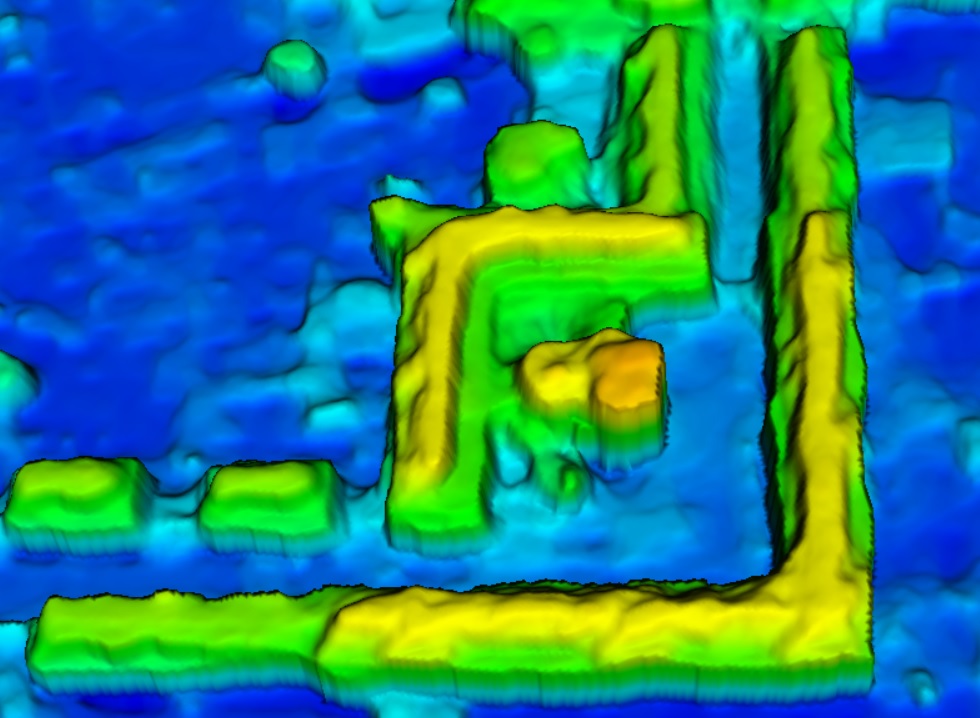
DTM-Generierung aus Satelliten- und Luftbilddaten
Inspiriert von den jüngsten Erfolgen im Bereich der Deep-Learning-Forschung erforscht unser Team aktiv die Anwendung von tiefen, neuronalen Netzen für die Extraktion von digitalen Geländemodellen (DTM) aus digitalen Oberflächenmodellen (DOMs). Unser Ansatz konzentriert sich auf die Entwicklung einfacher, aber effizienter Netzwerkarchitekturen mit einer geringeren Anzahl von Parametern im Vergleich zu weit verbreiteten Modellen. Diese Architekturen sind darauf ausgelegt, detaillierte DGMs aus DOMs zu generieren.
Unsere Methode arbeitet unabhängig von vordefinierten Schwellenwerten und eignet sich auch für schwierige Geländetypen wie steile Hänge, bewachsene Flächen und Gelände mit diskontinuierlichen Merkmalen. Ein wichtiges Ziel unseres Teams ist es, die Generierung von DGMs durch Deep Learning zu verbessern, indem wir ein einziges, umfassendes Modell erzeugen, das sich auf Daten von verschiedenen Sensoren mit unterschiedlichen Bodenauflösungen (GSDs) verallgemeinern lässt.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
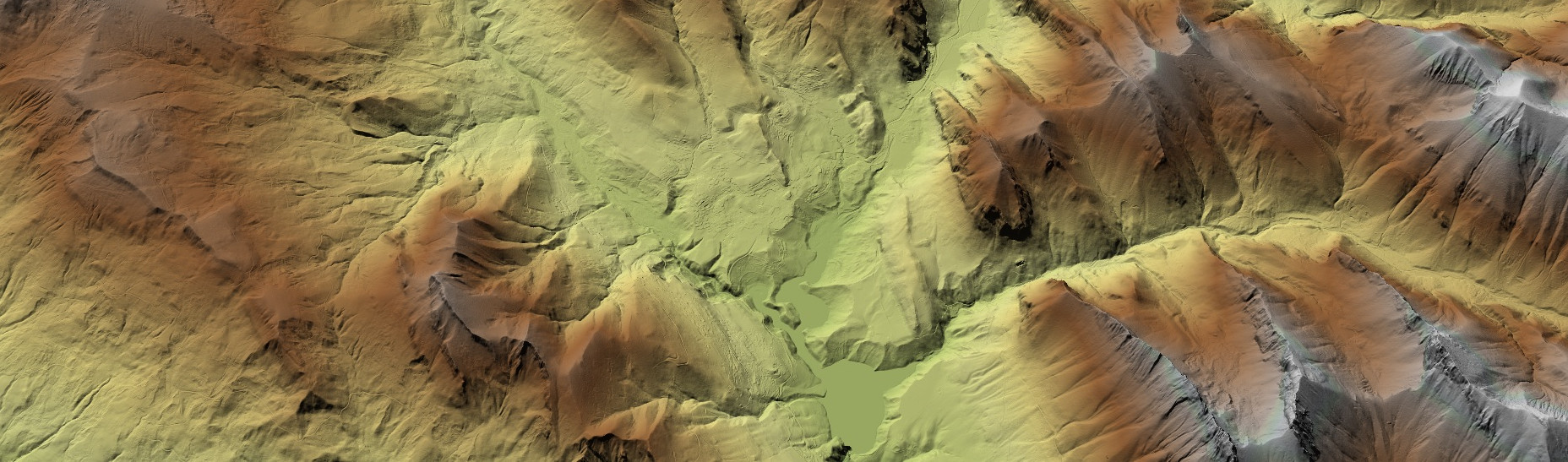
DOM Super-Resolution
Inspiriert von den bahnbrechenden Fortschritten im maschinellen Sehen, widmet sich unser Team auch der Verbesserung der Auflösung von Digitalen Oberflächenmodellen (DOMs) mit Hilfe eines neuartigen Ansatzes. Wir konzentrieren uns auf die Superauflösung von realen DOM-Daten mit geringer Auflösung, indem wir traditionelle, lernfreie Techniken mit der Leistungsfähigkeit von Deep Learning kombinieren. Um diesen Prozess zu steuern, nutzen wir multimodale Informationen für zusätzliche Genauigkeit. Ziel der Forschungsarbeiten ist die Entwicklung einer Lösung zur Verbesserung der DOM-Auflösung, die in diversen realen Szenarien anwendbar ist.
Die Forschungsgruppe trägt dazu bei, das Verständnis von Satellitenbildern zu verbessern, indem sie neue und verbesserte Algorithmen entwickelt, die auf leistungsstarken Werkzeugen des Deep Learning basieren. Außerdem erforscht die Gruppe für jedes der genannten Themen Datenfusionsstrategien, vor allem die Integration von multimodalien Datenquellen, wie Spektral- und Höheninformationen abgeleitet aus Satellitenbilddaten und öffentlich verfügbare Datensätze, wie z.B. Straßenansichten von Google Earth, um eine möglichst detaillierte Rekonstruktion von Gebäudegeometrien in Stadtmodellen zu erreichen.