KIFAHR: KI-basierte Vertikaldynamik-Steuerung

Im Automobilbereich besteht das Ziel der Vertikaldynamik-Konstruktion darin, die Fahrwerksaufhängung des Fahrzeugs so zu optimieren, dass bestimmte Ziele wie Fahrkomfort und Fahrzeugstabilität erreicht werden. Das Hauptziel ist die gleichzeitige Maximierung des Fahrkomforts für die Fahrzeuginsassen und der Straßenhaftung der Reifen. Um einen höheren Automatisierungsgrad beim Reglerentwurf zu erreichen, sind neuartige Regelungsansätze erforderlich. Dabei sollten verschiedene Einflussfaktoren wie variable Lasten, unterschiedliche Fahrbahnoberflächen, Reifentypen, Reifendrücke und Wetterbedingungen berücksichtigt werden. Um dieses Ziel zu erreichen, haben sich der Fahrwerkshersteller KW automotive GmbH und die DLR-Abteilung Fahrzeugsystemdynamik im Projekt KIFAHR zusammengetan. Im Rahmen des Projekts wurde das Potenzial intelligenter Lernmethoden, insbesondere des Reinforcement Learning (RL), für die Steuerung semi-aktiver Dämpfer im Fahrwerksbereich aufgezeigt. Methoden des Verstärkungslernens stellen einen vielversprechenden Ansatz dar, um das Regelgesetz durch automatisierte Prozesse zu erlernen. Mehrere Veröffentlichungen haben die Leistungsfähigkeit von Reinforcement Learning im Bereich der Regelungstechnik vor allem für aktive Regelgrößen gezeigt. Die Anwendung von RL-Methoden auf semi-aktive vertikal-dynamische Regelsysteme ist jedoch ein neues Forschungsgebiet.
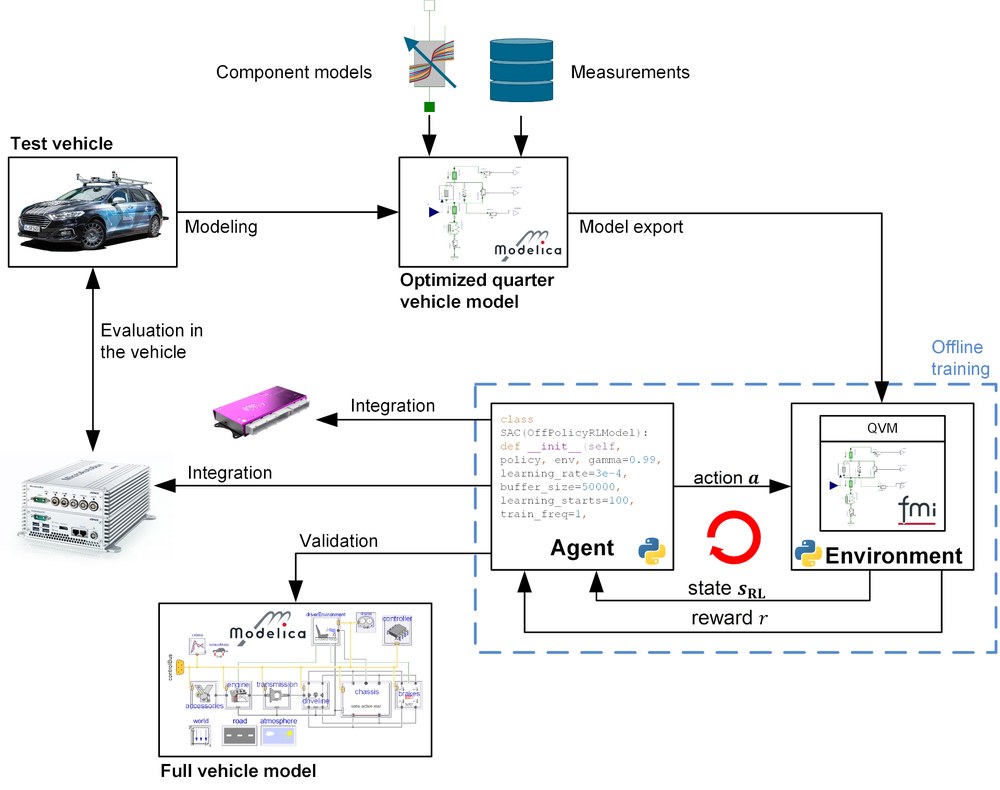
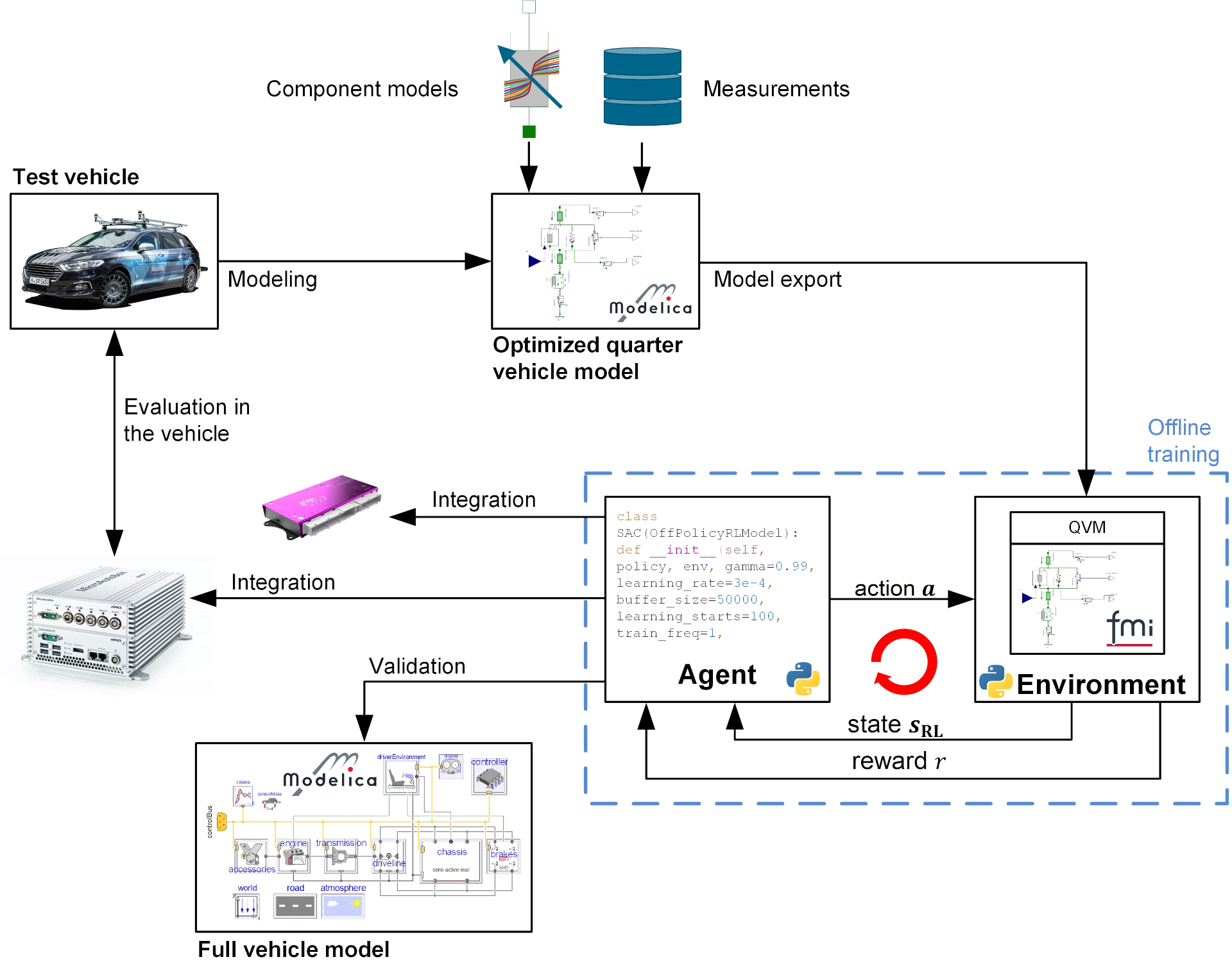
Das Projekt durchlief den gesamten RL-Toolchain-Prozess, der in der Abbildung unten dargestellt ist. Das Testfahrzeug für das Projekt ist das DLR-Abteilungstestfahrzeug AI For Mobility (AFM). Das Projekt begann mit der Erfassung umfangreicher Messdaten des gesamten Fahrzeugs auf dem KW automotive seven post Prüfstand und der Vermessung einzelner Komponenten, wie z.B. Buchsen oder Stoßdämpfer, auf verschiedenen High Fidelity Prüfständen. Nach Abschluss der ersten Phase wurden die gewonnenen Daten und das fundierte Systemwissen genutzt, um Trainingsmodelle der vertikalen Dynamik des Fahrzeugs für das RL-Training zu erstellen. Die DLR SR- eigenen Optimierungswerkzeuge und -bibliotheken unterstützten diesen Prozess maßgeblich. Während des Optimierungsprozesses wurden nicht nur die Parameter der Trainingsmodelle angepasst, sondern auch die Struktur des Modells optimiert. Darüber hinaus wurden je nach Verwendungszweck Fahrzeugmodelle unterschiedlicher Komplexität und Simulationsdauer erstellt. Zur Ermittlung der Dämpferdynamik wurden sowohl datenbasierte Modellierungsmethoden auf der Grundlage neuronaler Netze als auch physikalisch motivierte Methoden verwendet.
Für das Training des Reglers, den Export des neuronalen Netzes des Reglers und die Validierung des Reglers wurden neue Software-Toolchains entwickelt oder bestehende Toolchains umfassend erweitert und für den Anwendungszweck angepasst. Das Trainingsmodell wurde validiert und in die neu angepasste RL-Toolchain aufgenommen. Die Toolchain ist in der Lage, RL-Algorithmen automatisch in verschiedenen Umgebungen zu trainieren, einschließlich verschiedener Trainingsszenarien, und die erhaltenen Agenten anhand bestimmter Bewertungsmetriken und Szenarien zu vergleichen. Nach mehrmaliger Wiederholung und Optimierung des Trainingsprozesses wurden die besten Agenten für die Validierung an einem vollständigen Fahrzeugmodell ausgewählt. Um die Leistung des erlernten Steuergeräts zu bewerten, wurde der Agent als C-Code exportiert und in ein Rapid-Control-Prototyping-System integriert. In einem letzten Schritt wurde die Leistung des gelernten Controllers auf dem Sieben-Post-Test-Rig evaluiert und mit einem modernen kombinierten Skyhook & Groundhook Controller verglichen. Um einen angemessenen Vergleich zu erhalten, wurden die Parameter des Skyhook & Groundhook Controllers auch durch numerische Optimierung der Trainingsmodelle der Kontrollanlage ermittelt. Zusammenfassend lässt sich sagen, dass im Rahmen des Projekts ein neuer und leistungsfähiger KI-basierter Controller für die Steuerung der Vertikaldynamik entwickelt und mittels einer Toolbox zur Codegenerierung für neuronale Netze auf einem fahrzeuginternen Mikrocontroller implementiert wurde. Um die sichere Ausführung des Controllers gewährleisten zu können, wurde ein Sicherungskonzept entwickelt und in realen Fahrversuchen getestet.
Die Leistung des mit Hilfe eines validierten Regelstreckenmodells erlernten RL-basierten Reglers wurde sowohl qualitativ in realen Fahrversuchen als auch quantitativ durch Messungen auf dem Sieben-Säulen-Vertikaldynamikprüfstand bestätigt. Zusammenfassend lässt sich sagen, dass Methoden des Verstärkungslernens für die Steuerung der Vertikaldynamik bei einer Vielzahl von Fahrmanövern qualitativ und quantitativ besser abschneiden können als der Stand der Technik. Die Ergebnisse des Projekts zeigen das Potenzial von RL-Methoden für Anwendungen der Vertikaldynamikkontrolle. Im Rahmen des Projekts wurden neue leistungsstarke Software-Tools und leistungsfähige Hardware entwickelt, die den RL-Designprozess unterstützen und einen sicheren Betrieb gewährleisten. Weitere Forschung wird sich mit der Verfeinerung des gesamten Prozesses mit Technologien wie dem physikalisch informierten Lernen befassen.

{kind=link}