KIFAHR: AI-based vertical dynamic control

KIFAHR: AI-based vertical dynamic control
In the automotive sector, the aim of vertical dynamic design is to optimise the vehicle's chassis suspension in such a way that certain objectives such as ride comfort and vehicle stability are achieved. The main objective is to maximise ride comfort for the vehicle occupants and road grip for the tyres at the same time. In order to achieve a higher degree of automation in controller design, new control approaches are required. Various influencing factors such as variable loads, different road surfaces, tyre types, tyre pressures and weather conditions should be taken into account. To achieve this goal, the suspension manufacturer KW automotive GmbH and the DLR Vehicle System Dynamics department have joined forces in the KIFAHR project. As part of the project, the potential of intelligent learning methods, in particular reinforcement learning (RL), for the control of semi-active dampers in the chassis area was demonstrated. Reinforcement learning methods represent a promising approach for learning the control law through automated processes. Several publications have shown the efficiency of reinforcement learning in the field of control engineering, especially for active control variables. However, the application of RL methods to semi-active vertical dynamic control systems is a new field of research.
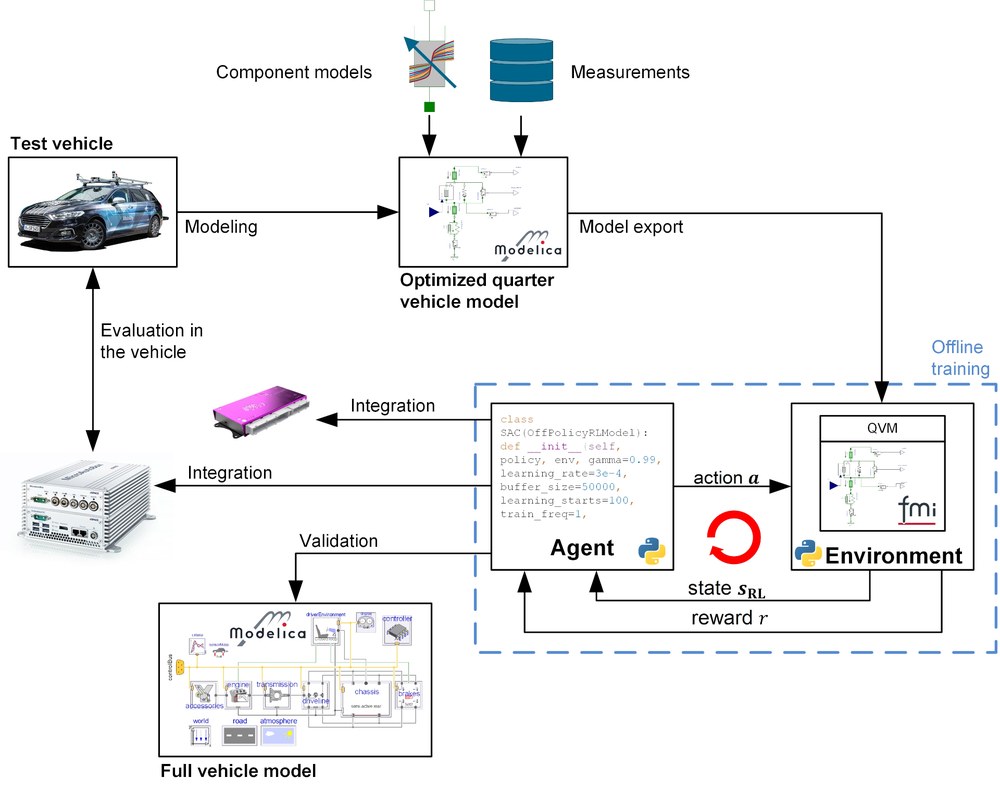
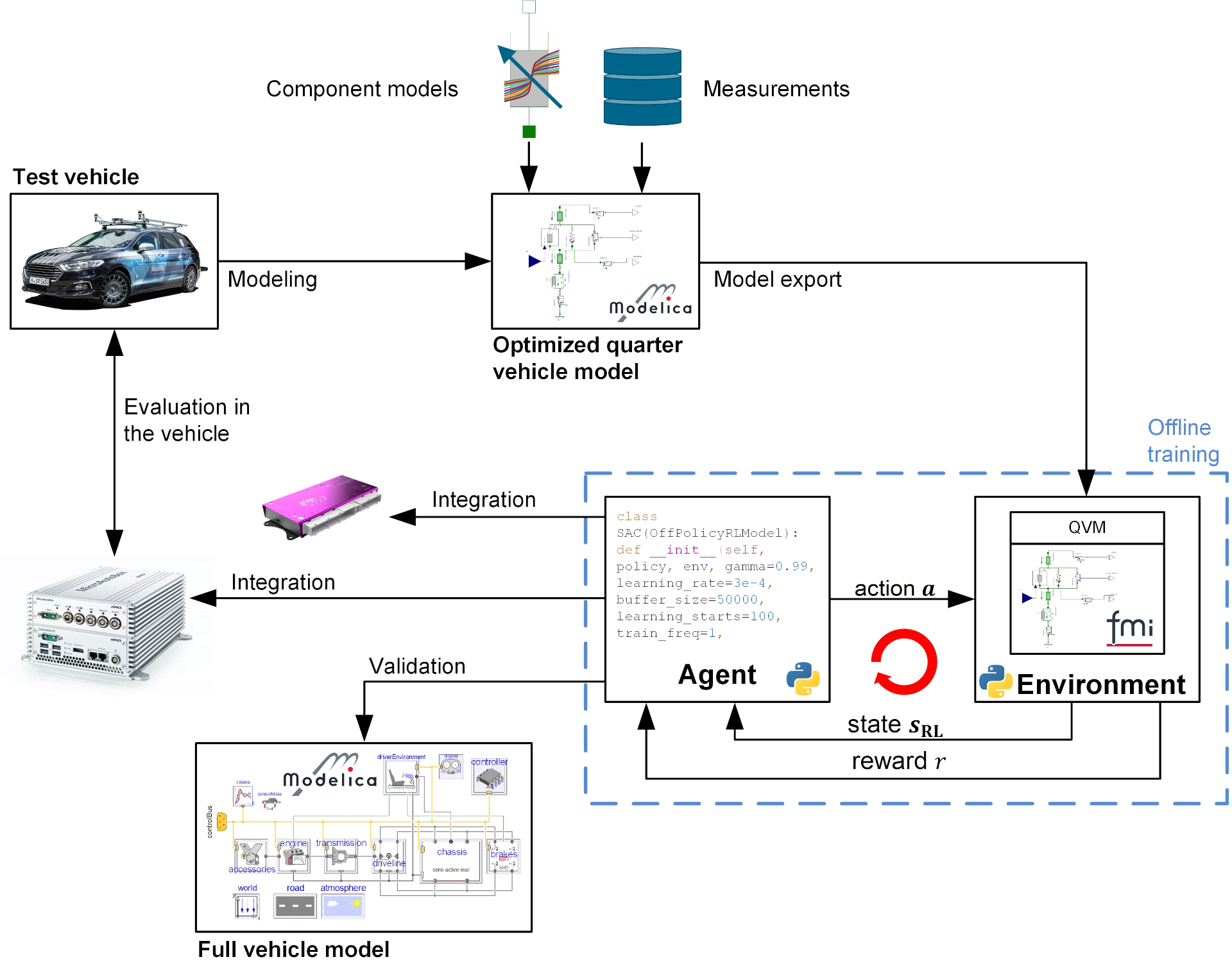
The project went through the entire RL toolchain process, which is shown in the figure above. The test vehicle for the project is the DLR departmental test vehicle AI For Mobility (AFM). The project began with the acquisition of extensive measurement data of the entire vehicle on the KW automotive seven post test bench and the measurement of individual components, such as bushings or shock absorbers, on various high fidelity test benches. After completion of the first phase, the data obtained and the in-depth system knowledge were used to create training models of the vehicle's vertical dynamics for RL training. DLR SR's own optimisation tools and libraries provided significant support for this process. During the optimisation process, not only were the parameters of the training models adjusted, but the structure of the model was also optimised. In addition, vehicle models of varying complexity and simulation duration were created depending on the intended use. Both data-based modelling methods based on neural networks and physically motivated methods were used to determine the damper dynamics.
To train the controller, export the controller's neural network and validate the controller, new software toolchains were developed or existing toolchains were extensively expanded and adapted for the application purpose. The training model was validated and incorporated into the newly customised RL toolchain. The toolchain is able to automatically train RL algorithms in different environments, including different training scenarios, and compare the resulting agents based on specific evaluation metrics and scenarios. After repeating and optimising the training process several times, the best agents were selected for validation on a full vehicle model. To evaluate the performance of the learnt ECU, the agent was exported as C code and integrated into a rapid control prototyping system. In a final step, the performance of the learnt controller was evaluated on the seven-post test rig and compared to a modern combined skyhook & groundhook controller. In order to obtain an appropriate comparison, the parameters of the skyhook & groundhook controller were also determined by numerically optimising the training models of the control system. To summarise, a new and powerful AI-based controller for controlling vertical dynamics was developed as part of the project and implemented on an in-vehicle microcontroller using a neural network code generation toolbox. A safety concept was developed and tested in real driving tests to ensure the safe execution of the controller.
The performance of the RL-based controller learnt using a validated controlled system model was confirmed both qualitatively in real driving tests and quantitatively by measurements on the seven-post vertical dynamics test rig. In summary, reinforcement learning methods for the control of vertical dynamics can perform qualitatively and quantitatively better than the state of the art in a variety of driving manoeuvres. The results of the project show the potential of RL methods for vertical dynamics control applications. As part of the project, new powerful software tools and high-performance hardware were developed to support the RL design process and ensure safe operation. Further research will look at refining the whole process with technologies such as physically informed learning.


{kind=link}